Probability and the problem of the single case
Repeated Events
How would you make sense of the statement
The chance this coin comes up heads is 50%
I think there’s a pretty straightforward answer to this. If you flipped the coin over and over again, the proportion of heads that you’d see would tend towards 1/2 as the number of flips tended towards infinity.
This relies on the ability to repeat an experiment over and over again. So what if there’s a random event that will happen exactly one time?
Single Event
How would you make sense of the statement
The chance the next coin flip is heads is 50%”
This is a lot harder! Here are few possible responses:
Response #1: The statement is nonsense
One possible response is “you’re doing it wrong”. That statement makes no sense because probability fundamentally relies on the ability to repeat events. One-shot events are outside the scope of probability. It will either be heads or tails - it will never be 50% heads.
While this sounds technically plausible, I’m not really willing to give up on using probability for single events because… it’s just so useful! I’m not sure how I would operate in the world if I was not allowed to use probabilistic thinking to make decisions for events that happen exactly once.
Response #2: It represents incomplete information
Informally, this response suggests that the 50% probability stems from our lack of knowledge and therefore inability to predict the outcome. Given what we know, we’d guess there’s a 50% chance the coin will be heads. The term “credence” is often used to indicate this interpretation, e.g. “I have a 50% credence that a fair coin will land on heads the next time it is flipped”.
We haven’t talked about whether the universe is deterministic or fundamentally random yet, but this response survives even a deterministic universe. With perfect information the coin may be gauranteed to come up heads, but with the very incomplete information that I have, my best guess is 50%.
Although that feels quite intuitive, it also feels extremely subjective. So probability is just whatever we want to believe? Can two people with the same information disagree on the probability of an event since, after all, it’s just a personal credence?
Here’s one idea that I’ve been toying with that removes the subjectivity while keeping the central idea of limited knowledge. It borrows ideas from statistical mechanics.
Statistical mechanics
In statistical mechanics, you have notion of microstates and macrostates. A microstates represents all the information: the location and velocity of every particle, every particle’s quantum spin, and whatever else you need to describe the entire system in full detail. A macrostate is a much more coarse-grained description of a system. Many microstates can correspond to the same macrostate. An example with help make this clear.
Let’s say we have an image made up of 100 x 100 pixels that each can be either white or black. A microstate would be a description of every single pixel and whether it’s white or black. You could visualize this as a binary string of 1’s and 0’s that’s 10,000 bits long. How many microstates are there? \(2^{10000}\).
A macrostate is harder to define precisely, but it’s generally a coarse-grained description of the system. One potential macrostate could be “all black”. How many microstates correspond to the macrostate of “all black”? Naively, 1 - every pixel has to be black. But here’s where the limited knowledge comes in. I posit that if I pick a random pixel and turn it white, you’d still think the image was “all black”. Your eyes are not precise enough to really distinguish between the microstate where every single pixel is black and the 10,000 microstates where one pixel is white and the rest are black. So now we have 10,001 microstates that all correspond to the macrostate of “all black”.
The best explanation of these concepts that I’ve ever seen is in this youtube video.
Where does probability come in? What if I asked “What’s the probability that there are any white pixels in an ‘all black’ image?”. Given our description above, I guess it’s \(\frac{10000}{10001}\). Nothing is random here, we just don’t know which microstate we’re in given the macrostate.
Bringing it back
How can we apply the concepts of micro and macrostates to make sense of the statement “The chance the next coin flip is heads is 50%” while avoiding probability becoming completely subjective like credences?
We can interpret the statement to mean, given the current macrostate, what proportion of the microstates that I could be in that would result in the next coin flip coming up heads?
Put another way, there are many variables about the world that could change without you noticing. The coin that you’re flipping could be made up of vastly different numbers of copper atoms, and you wouldn’t be able to tell the difference. Maybe in some of those cases, the coin would come up heads while in others it would come up tails.
Response #3: It represents fundamental randomness
Here’s a totally different way to make sense of the statement “The chance the next coin flip is heads is 50%”.
Quantum mechanics suggests that we live in a fundamentally random universe. Randomness is not due to a lack of information. Even if you know the precise microstate of the entire universe, you still couldn’t predict with certainty what would happen next.
I don’t claim to fully understand the details here, but quantum mechanics says that if you know the state of the universe, you can use the Schrödinger equation to “evolve the system forward in time” (i.e. predict the future). The key point, though, is that the Schrödinger equation produces a “wave function” that represents a probability distribution over many possible outcomes. So, even with complete information, it makes a probabilistic prediction for what will happen next.
If we accept the fact that the universe is fundamentally random, then it’s again quite easy to make sense of the statement “The chance the next coin flip is heads is 50%”. We’re saying that given the state of the universe, the Schrödinger equation predicts a 50% chance that the coin will come up heads next and a 50% chance that the coin will come up tails next. It’s a pretty literal interpretation.
A fun philosophical tangent is to consider the many-worlds interpretation of quantum mechanics which posits that all possible outcomes of quantum measurements are physically realized in some “world”. In this interpretation, it’s almost as if we’re back in the “repeated events” case even for things that will only happen once. We can just treat each possible worlds as a data points in our cosmic experiment.
So which is it?
Which of these interpretations is right? Obviously I don’t know!
But if I had to guess, I’d say that most of the time when we talk probabilistically about a single event, we’re likely representing our incomplete information about the world. I suspect that the fundamental randomness of the universe does play a part, but it’s a smaller one.
Single Deterministic Event
Let’s take this one further. Let’s talk about a single event that’s very clearly deterministic.
Consider the following Sudoku puzzle:
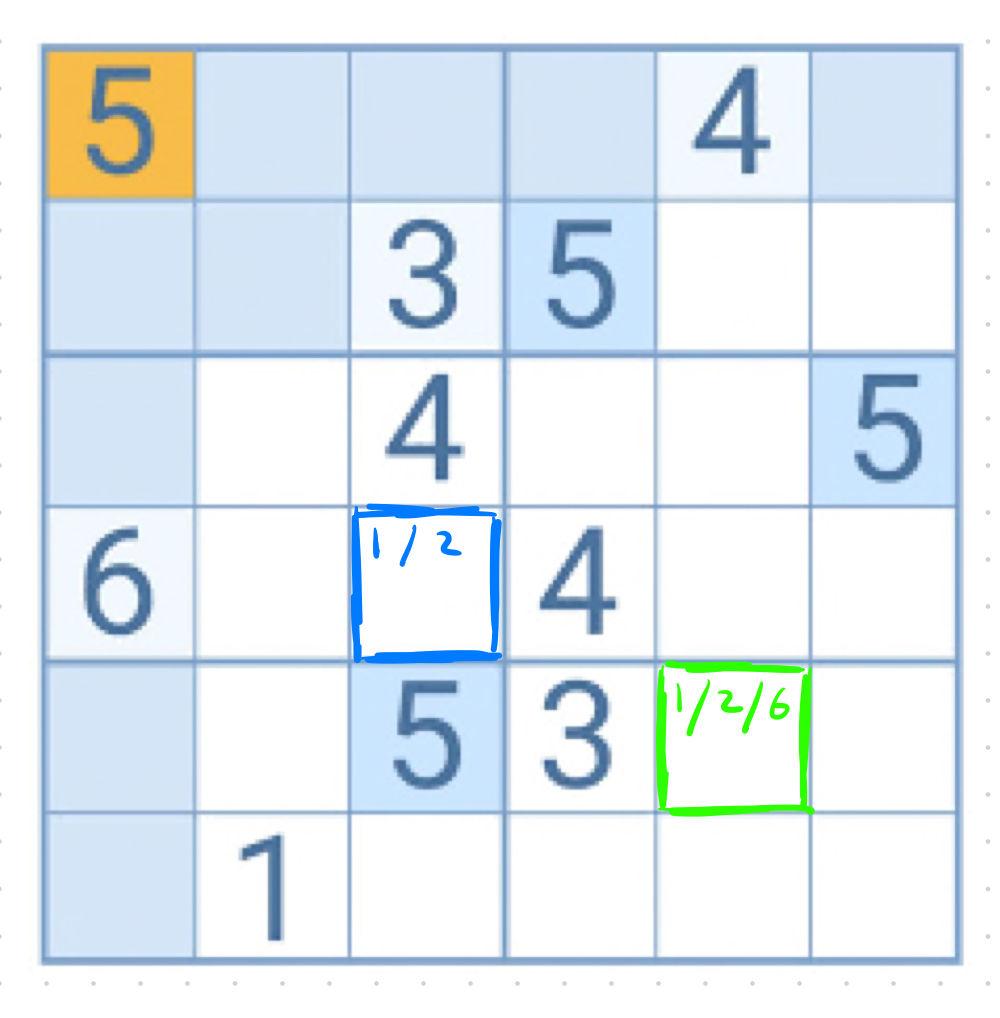
I can quickly tell that the blue square could be either a 1 or a 2, while the green square could be a 1, 2, or 6. It’s not obvious to me which of those choices is right. Even though it’s never technically necessary, let’s say I’m kind of stuck and I want to make a guess.
The following statement feels intuitively right to me:
I’m more likely to be correct if I guess 2 for the blue square than if I guess a 6 for the green square.
Why? Well I’ve narrowed the blue square down to 2 possibilities, which means I have a 1/2 chance of being right if I guess, whereas the green square still has three possibilities leaving me with a 1/3 chance of being right if I guess.
But wait… if I guess 2 for the blue square, there’s clearly no randomness involved in whether I’m right or wrong. The correct answer is either a 1 or a 2 and that’s determined already, regardless of my choice. So really I have either a 0% chance or a 100% chance of being right.
If we consider our three responses to the single coin-flip event above, the fact that there is absolutely no randomness in this example completely rules out response #3. So we are left with response #1 (the statement is nonsense) and response #2 (the statement represents incomplete information). At first glance, both seem plausible in this situation.
Response #2: It represents incomplete information
Let’s consider response #2 first. Although Sudoku is a game of complete information, it doesn’t feel that way from my perspective. Let’s treat every fully filled in board as a microstate, half of them have a 1 in the blue square and half of them have a 2 in the blue square. Contrast that with the green square where only 1/3 of the possible microstates have a 6 in the green square. Even though they’re not, they all seem equally likely to me given the current state of the board. Put another way, I cannot distinguish between these microstates given the current macrostate.
So am I on solid ground making the statement “I’m more likely to be correct if I guess 2 for the blue square than if I guess a 6 for the green square.”? In contrast to the coin flipping example, the beauty of this example is that it’s easy enough that we can figure out the exact microstate that we’re in. Here is the solved board:
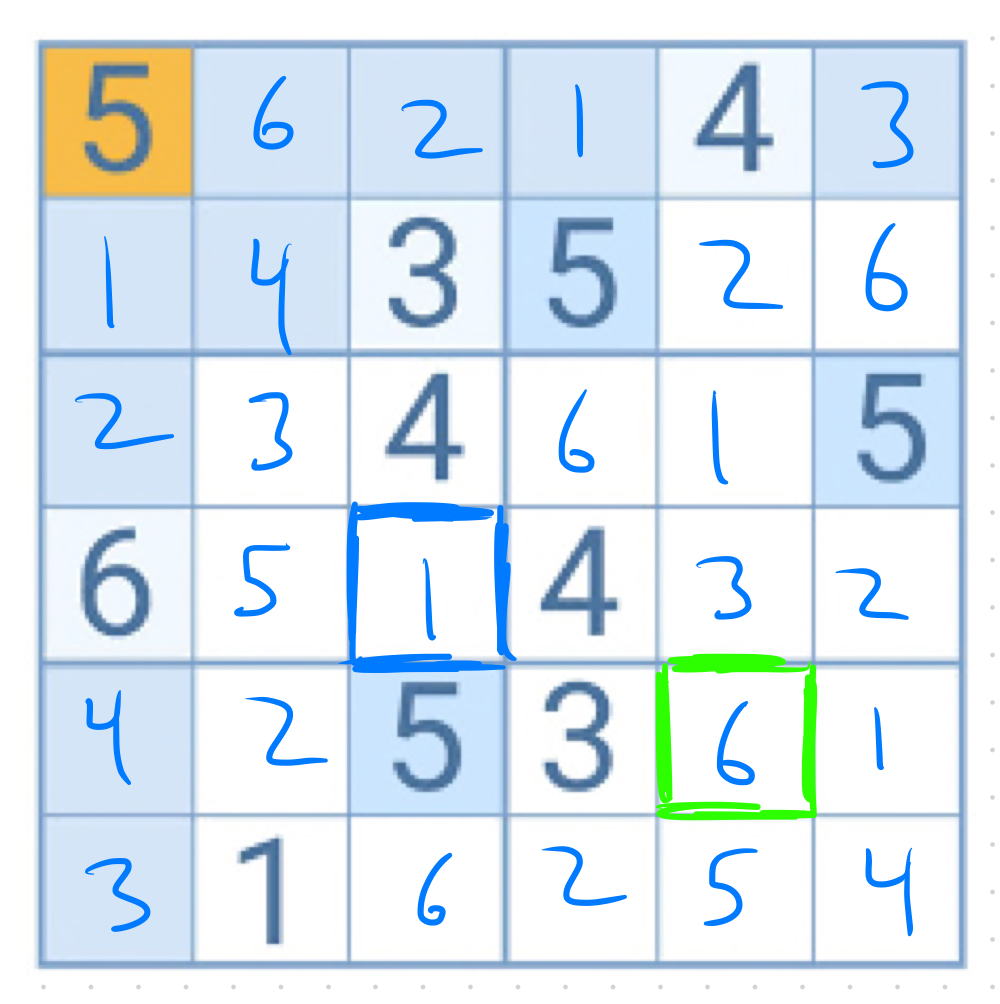
So, in the end, we are not more likely to be correct if we guess a 2 for the blue square than if we guess a 6 in the green square. The statement is just plain false.
Response #1: The statement is nonsense
This brings us back to response #1. In this case, this must be the correct response. The statement truly is nonsense since it’s flat-out wrong.
But that’s pretty unsatisfying… At a minimum, it feels like guessing on a square with two possibilities is a much better strategy than guessing on a square with 3. If you solved 1000 Sudoku boards using the strategy of “prefer guessing squares with fewer possibilities” I highly suspect you’ll finish faster than if you use the opposite strategy. Notice that by framing this choice as a general strategy that can be repeated, we put ourselves back into the “repeated events” case where it’s much easier to apply probability.
In this case, I think there’s an even simpler reframing that puts us on solid ground. Instead of saying “I’m more likely to be correct if I guess 2 for the blue square than if I guess a 6 for the green square.” let’s say this:
I’m more likely to be correct if I pick randomly between 1 and 2 for the blue square than if I pick randomly between 1, 2, and 6 for the green square.
That is clearly true. We now know that the blue square is a 1 and the green square is a 6. If you pick randomly on the blue square, you have a 50% chance of picking a 1. If you pick randomly on the green square, you have a 1/3 chance of picking a 6. You are more likely to be correct if you pick randomly on the blue square.
In summary
In the Sudoku example, the correct response turned out to be response #1. Our original statement was false. But we were able to recover a true statement with a slight reframing. Furthermore, I claim this true statement is actually what I was trying to say even when I made the false statement. The two statements feel extremely similar to me even though one is true and one is false.
Maybe this applies to the single coin-flip event as well. Maybe the statement “The chance the next coin flip is heads is 50%” is nonsense but we can reframe it ever so slightly to produce a true statement while preserving the intuition. I haven’t found the correct reframing yet, but that doesn’t mean it doesn’t exist.