How to remember linear regression
Linear regression is one of the most useful tools in statistics, but the formula is a little hard to remember. If you’re trying to find the “best fit” \(x\) in the equation \(Ax \approx b\), here is the solution:
\[(A^T A)^{-1} A^T b\]If you’re expecting me to be able to produce that formula from memory… don’t hold your breath.
However, if you understand what a linear regression is, then re-deriving this formula is actually shockingly easy. And, importantly, remembering “what a linear regression is” is much easier than remembering some (relatively) complicated formula. I suspect this is often true - that remembering how to derive a formula from simple ideas is easier than remembering the formula itself.
An aside: I often struggle with finding the appropriate level at which to target my explanations. Ideally, I’d like to assume no previous knowledge and explain things from scratch, but then the posts become so long as to be useless. But if I explain things too tersely, the only people following along are the people who already understand the explanation! So, in this case, I’m going to write two versions: a short version and a long one.
What is a linear regression: the short version
With real life (noisy) data, there won’t be an exact solution to the equation \(Ax = b\). Put another way, \(b\) does not live in the column space of \(A\). We need to find a vector which does live in the column space of \(A\) and which minimizes the squared errors between itself and \(b\). Let’s call this vector \(b^*\).
What are the errors between \(b^*\) and \(b\)? Simply \(b - b^*\), which is itself another vector. Let’s call this \(\epsilon\) (for errors). We don’t care about the errors themselves as much as the sum of the squared errors, which is just the squared length of \(\epsilon\).
To recap, we want to find the \(b^*\) that lives in the column space of \(A\) and which minimizes the length of \(\epsilon\). Note that our three vectors form a triangle, i.e. \(b^* + \epsilon = b\). At this point, the solution might become clear. If we take \(b^*\) to be the projection of \(b\) onto the column space of \(A\), then \(b^*\) and \(\epsilon\) will form a right triangle with hypotenuse \(b\), and that will minimize the length of \(\epsilon\).
If that’s not obvious, consider a line \(A\) and a point \(b\) which is not already on the line. What’s the minimum distance from \(b\) to \(A\)? It’s the distance of the line which connects \(b\) to \(A\) and which is perpendicular to \(A\), i.e. it’s the line between \(b\) and \(b\)’s projection onto \(A\).
That’s all you have to remember in order to derive the formula for linear regression.
\[\begin{align*} Ax &= b^* \tag{1} \\ A \bot (b - b^*) \tag{2} \\ A \bot (b - Ax) \tag{substitute 1 into 2} \\ A^T (b - Ax) &= 0 \tag{the definition of perpendicular} \\ A^T b - A^TAx &= 0 \\ A^T b &= A^TAx \\ (A^TA)^{-1} A^T b &= x \tag*{$\square$} \\ \end{align*}\]What is a linear regression: the long version
In general, a linear regression is trying to find coefficients to a linear equation that minimize the sum of the squared errors. For example, let’s say you think there’s roughly a linear relationship between the square footage of a house (sqft), the median price of all houses in that house’s neighborhood (medprice), and the price of the house (price), i.e.
\[\mathrm{price} = c_2 (\mathrm{sqft}) + c_1 (\mathrm{medprice}) + c_0\]Furthermore, you have some data. For each data point (house), you have the three relevant values (sqft, medprice, and price). We can organize this data into a single equation, \(Ax=b\), using matrices where:
\[\overset{A}{ \begin{bmatrix} \vert & \vert & \vert \\ \mathrm{sqft} & \mathrm{medprice} & 1 \\ \vert & \vert & \vert \\ \end{bmatrix} } \overset{x}{ \begin{bmatrix} c_2 \\ c_1 \\ c_0 \end{bmatrix} } = \overset{b}{ \begin{bmatrix} \vert \\ \mathrm{price} \\ \vert \\ \end{bmatrix} }\]Each row in \(A\) will contain the two predictor values (sqft and medprice) for a given home, along with a constant 1 (to account for the \(c_0\) in our linear equation) and the corresponding row in \(b\) will have the responder variable (price).
Now, importantly, this equation will almost always have no solution. To understand why, notice that we are trying to find a linear combination of the three columns of \(A\) that equals the vector \(b\). We haven’t yet specified how many data points we have, but for the sake of this part of the explanation let’s assume it’s 100. That means we have a vector \(b\) which lives in a 100-dimensional space. If that throws you for a loop, think about how a vector with 2 elements lives in the x-y coordinate plane - a 2-D space, while a vector with three elements lives in the x-y-z coordinate system - a 3-D space. So, the vector \(b\) - with 100 elements - lives in a 100-dimensional space. So do the columns of \(A\). They are, after all, each vectors with 100 elements.
If you consider a single column of \(A\) by itself, and take all linear combinations of it (i.e. you scale it by any value), you will end up with a single line in that 100-dimensional space. We call that a 1-D subspace of the 100-dimensional space. If you consider two columns of A, and take all linear combinations of them, you will end up with a 2-D subspace (a plane through the origin) within that 100-dimensional space. And, probably obviously now, if you consider all three column vectors of A, and take all linear combinations of them, you will end up with a 3-D subspace of the 100-dimensional space. To throw some terminology at you, that 3-D subspace is spanned by the three column vectors of \(A\), and it called the column space of A.
Understanding how linear combinations of vectors span a space is critical, so I’ll include the following gif from 3Blue1Brown to help you understand it visually. Notice how by changing the coefficients \(a\) and \(b\), their linear combination (\(av + bw\)) can point anywhere in the plane. That means they span the plane.
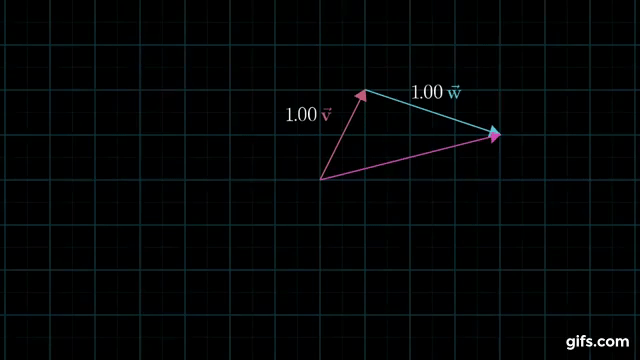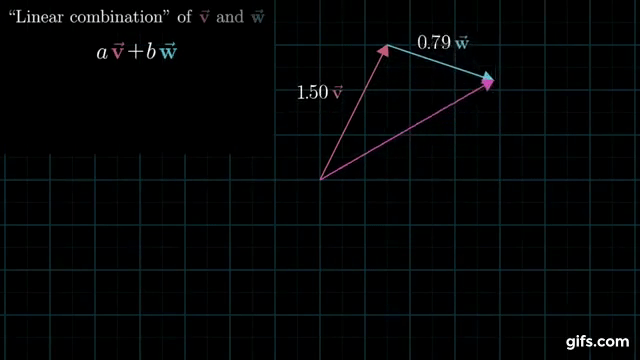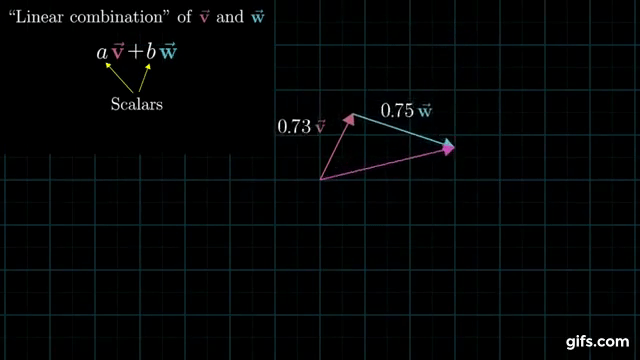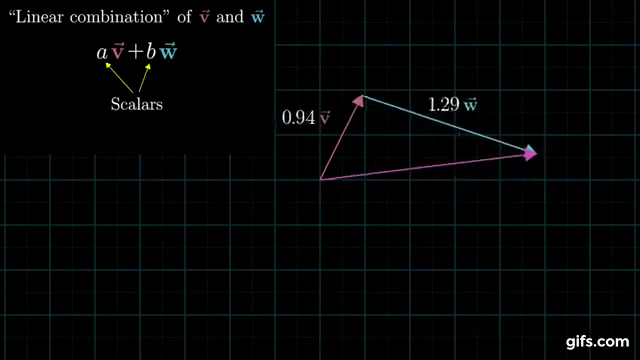
I previously said that it’s unlikely that our equation \(Ax = b\) has a solution. Why is that? We can now understand that our equation only has a solution if the 100-dimensional vector \(b\) happens to lie within the 3-dimensional column space of \(A\). That’s kind of like hoping that a bunch of points in 3-D space happen to fall exactly on a single (1-D) line (although a much more extreme version of that). It might happen, but with real data that likely has some noise in it, it’s extremely unlikely.
So, since there’s no solution, we can’t just solve the equation directly by computing \(x = A^{-1}b\). In fact, why don’t we stop writing \(Ax=b\), because that’s a little misleading given there’s no solution (it’s like writing \(5x = 1\) and \(2x = 2\), solve for \(x\)). Instead, let’s write \(Ax = b^*\), where we assert that this equation has a solution. In other words, the only candidates for \(b^*\) are the vectors in the column space of \(A\).
The next step is to figure out which \(b^*\) is “best”. Linear regression is defined as trying to minimize the squared errors, so we want the \(b^*\) that minimizes the sum of the squares of the elements of \(b - b^*\). At this point, I’m going to refer you to the short version. I’ve hopefully filled in the relevant background information to make that explanation accessible.